Abstract
Large language models (LLMs) have the potential to tackle sequential decision-making problems due to their generalist capabilities. Instead of optimizing "myopic" surrogate objectives such as human preferences within a single turn, in such problems, we wish to directly optimize long-term objectives, such as user satisfaction over an entire dialogue with an LLM or delayed success metrics in web navigation. Multi-turn reinforcement learning (RL) provides an appealing approach to directly optimize long-term objectives, but how can we design effective and efficient multi-turn RL algorithms for LLMs? In this work, we propose an algorithmic framework to multi-turn RL for LLMs that preserves the flexibility of token-by-token RL used in single-turn RL problems, while still accommodating long horizons and delayed rewards more effectively. Our framework, the Actor-Critic Framework with a Hierarchical Structure (ArCHer), combines a high-level off-policy RL algorithm that trains a value function with a low-level RL algorithm that trains a token-by-token policy. While ArCHer can be instantiated with multiple RL algorithms, a particularly convenient instantiation is to use temporal difference (TD) learning at the high level and on-policy token-level policy gradient at the low level. Empirically, we show that ArCHer significantly improves efficiency and performance of multi-turn LLM tasks, attaining sample efficiency boosts of about 100x over prior on-policy methods and converging to a much better performance than other off-policy methods.
What is Multi-Turn RL for language?
Generalist LLMs have the potential of serving as language agents to navigate through the web, make use of external tools, interact with human, and etc. In order to succeed in these problems, an LLM needs to make a sequence of intelligent decisions over multiple turns of interaction with an external environment.
- Most prior works for RL for LLMs focus on optimizing greedily for single-turn human preferences (single-turn RLHF), and policies trained in this way lack strategic planning over a long horizon
- ArCHer directly apply "multi-turn" RL to directly maximize the long-term objective of interest (e.g., customer satisfaction at the end of a multi-turn conversation with an LLM assistant), which can be formulated as scalar rewards.


Why do we need a hierarchical structure for RL with LLM?
Prior works in RL for LLMs either run entirely at the token level or at the utterance (a sequence of tokens) level, but they face different challenges:
- Token-level methods face the challenge of an extremely long horizon (number of tokens per round * number of interactions), leading to numerical instabilities and slow convergence
- Utterance-level methods face the challenge of an exponential action space (exponential in the number of tokens per utterance), resulting in difficulty in optimizing over such large action space
Our ArCHer for RL with language models can enjoy the best of both worlds, where an off-policy temporal difference learning method can train an utterance-level value function at the high level, and any policy gradient algorithm can optimize the token generation at each turn of the interaction at the low level, treating the high-level value function as the terminal reward for that turn.
This allows for sample reuse and faster convergence, while avoiding the need to perform Bellman backups over each individual token, as the high-level critic is trained at a coarser time-scale given by utterances. It also directly inherits tuning implementations from any existing token-level policy gradient algorithm that has been developed for single-turn RL with preferences, but with the utterance-level value function inheriting the role of the reward model. This way we are able to obtain the best of both utterance-based and token-based, and off-policy and on-policy approaches for training LLMs.
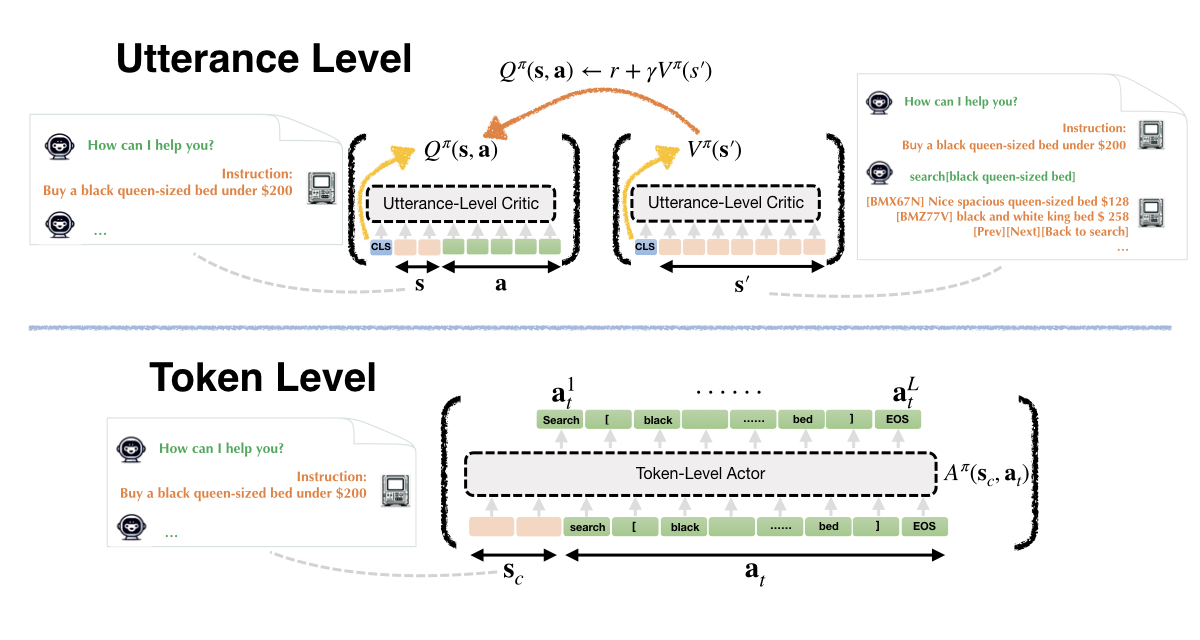
How does ArCHer work in practice?
We evaluate the performance of ArCHer on a wide range of tasks:
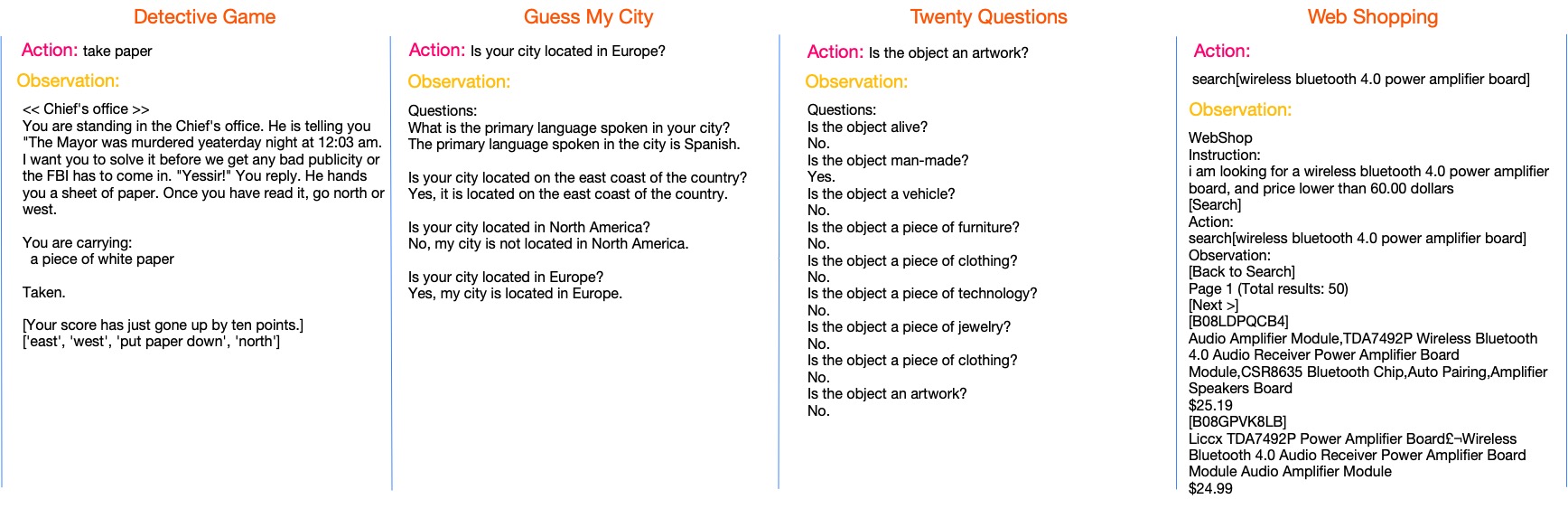
We present the sample complexity and final performance of ArCHer compared to state-of-the-art baselines:
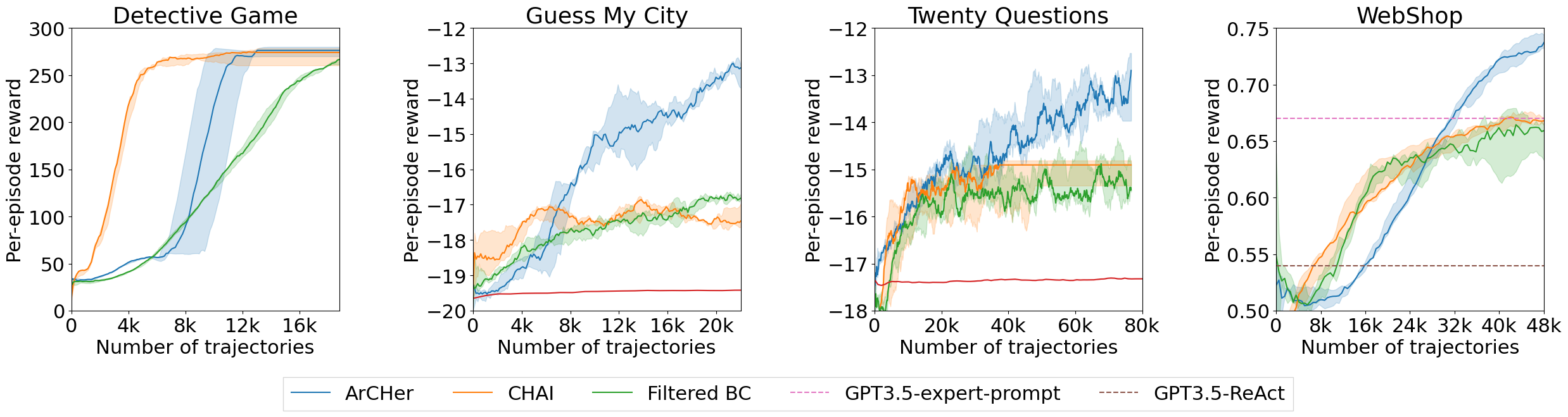
ArCHer achieves 100x better sample complexity than state-of-the-art on-policy method PPO and converges to a better performance than state-of-the-art off-policy methods. For more results and ablations, please refer to our paper!
BibTeX
@misc{zhou2024archer,
title={ArCHer: Training Language Model Agents via Hierarchical Multi-Turn RL},
author={Yifei Zhou and Andrea Zanette and Jiayi Pan and Sergey Levine and Aviral Kumar},
year={2024},
eprint={2402.19446},
archivePrefix={arXiv},
primaryClass={cs.LG}
}